Kleine gemeente, fijne gemeente? Over ‘het gemeenterapport’ van Het Nieuwsblad.
In Het Nieuwsblad vond u de voorbije week ‘Het Gemeenterapport‘. Het is de neerslag van een grootschalige enquête bij 116.000 Vlamingen die peilde naar verschillende lokale thema’s en het nieuwe gemeentebestuur.
Met de bevraging wou men bij Het Nieuwsblad en onderzoeksbureau iVox onder andere weten in welke gemeenten we het liefste wonen. Men deed dit door die 116.000 Vlamingen te laten antwoorden op de vraag ‘Hoe graag woont u in uw gemeente?‘ met een score tussen 0 en 10. Hieronder de resultaten zoals ze gepresenteerd werden door Het Nieuwsblad (eigen reproductie op basis van de beschikbare gegevens):
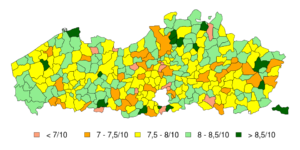
Men heeft de gemiddelde score voor elke gemeente berekend en op basis van een kleurcode de kaart van Vlaanderen ingekleurd. In de inleiding van het artikel schrijft Het Nieuwsblad:
Inwoners van Linkebeek, Vorselaar en Zutendaal wonen het liefst in hun gemeente. Tienen, Vilvoorde en Zelzate scoren dan weer het slechtst. Dat blijkt uit Het Gemeenterapport van Het Nieuwsblad.
Het Nieuwsblad – 20/01/2014
Maar kunnen we dit nu al besluiten? Deze conclusie is namelijk niet zo vanzelfsprekend als we zouden denken.
Steekproef
Een vragenlijst die werd afgenomen bij meer dan 116.000 Vlamingen lijkt heel erg betrouwbaar te zijn. De steekproef is in elk geval gigantisch groot. En zolang we op basis van die vragenlijst enkel conclusies trekken over ‘dé Vlamingen’ is er ook geen enkel probleem.
Echter, de bedoeling van Het Gemeenterapport is niet om over de Vlaming in het algemeen te rapporteren, maar wel om de resultaten te gaan vergelijken over de verschillende gemeenten heen. En dan is het niet de totale steekproefgrootte die van belang is, maar de steekproefgroottes voor elke gemeente afzonderlijk. Stel dat er slechts 1 inwoner van Linkebeek de enquête heeft ingevuld, maar bijna 7500 van de om en bij 7700 inwoners van Vorselaar reageerden. Beide gemeenten komen als aangenaam uit de bevraging, maar niemand zal eraan twijfelen dat het oordeel over Vorselaar dichter bij de waarheid zal liggen. Wanneer bijna elke inwoner een positief oordeel velt, kunnen we relatief zeker zijn dat het in Vorselaar aangenaam wonen is. Over Linkebeek zijn we daarentegen nog niet veel wijzer, misschien woont onze respondent in een goeie buurt, zijn de politici waarop hij heeft gestemd aan de macht of ligt eender welke subjectieve reden aan de basis van zijn positief oordeel. Misschien wijkt zijn mening af van de meerderheid. We weten het gewoonweg niet, want die is niet bevraagd.
De kern van het probleem zou hiermee duidelijk moeten zijn: de gemiddelde tevredenheidsscores zoals ze op bovenstaand kaartje zijn weergegeven kunnen moeilijk geïnterpreteerd worden zonder informatie over hoe betrouwbaar elke score is.
“Kleine gemeenten probleem”
Een probleem dat hieruit voortvloeit, is dat (in dit geval) gemeenten waar men slechts een kleine steekproef heeft genomen een veel grotere kans hebben om extreme uitkomsten te genereren. Hoe kleiner de steekproef, hoe groter de kans op extremen. Hoe dit meer bepaald in zijn werk kan gaan, kan je nalezen op mijn persoonlijke blog inclusief animatie.
Conclusie
Het kaartje van Het Nieuwsblad geeft te weinig informatie om de analyse ten gronde te kunnen voeren. Linkebeek, Vorselaar en Zutendaal halen inderdaad de hoogste scores, maar het zijn ook stuk voor stuk kleine gemeentes. Zonder extra informatie is het erg moeilijk om in te schatten of deze gemeentes ‘extreem’ scoren wegens bovenstaand steekproefprobleem, omdat we per toeval enkele enthousiaste inwoners te pakken hadden of omdat het daar echt zo fijn wonen is.
Het is des mensen om altijd en overal oorzakelijke verbanden te gaan zoeken/zien bij opmerkelijke waarnemingen. Zeker journalisten, opiniemakers, experten allerhande hebben deze neiging. En dat is een goeie zaak, want het is ook hun taak om dingen in perspectief te plaatsen. Maar het wordt problematisch wanneer men toevallige fluctuaties gaat verklaren.
Een meer formele en uitgebreide bespreking van bovenstaande ideeën kan in de paper ‘Gelman – All maps of parameter estimates are misleading‘ gevonden worden.
Auteur: Dries Benoit
Dries Benoit is professor bedrijfsstatistiek (business analytics) aan de faculteit Economie & Bedrijfskunde van de Universiteit Gent. Hij doceert de vakken ‘Bayesiaanse Statistiek’ en ‘Prijszetting en Omzetbeheer’. Zijn onderzoek situeert zich in het domein van de Bayesiaanse analyse met toepassingen binnen klantenbeheersystemen en prijszetting. Op zijn blog (taptoe.wordpress.com) geeft hij op een toegankelijke manier duiding bij actuele onderwerpen gelinkt aan statistiek of data-analyse.

